Top 40+ Database Engineer Interview Questions
Preparing for a technical interview? Whether you’re a beginner or an experienced professional, reviewing the most common Database Engineer Interview Questions can help you feel more confident and ready. In this guide, we’ve compiled over 40 essential questions that cover everything from database design and SQL to performance tuning and security. Let’s dive in and get you interview-ready!

40 Must Know Database Engineer Interview Questions
General Database Engineer Interview Questions
1. What is a transactional database?
2. What is an aggregate function in SQL?
3. What is the difference between CHAR and VARCHAR?
4. What is a database cursor?
5. What is a composite key?
SQL and Query Optimization Database Engineer Interview Questions
1. What is SQL injection and how do you prevent it?
2. What is a database transaction log?
3. What is the difference between an inner join and an outer join in SQL?
4. What are the various types of indexes in SQL?
Database Design & Modeling Database Engineer Interview Questions
1. What is a relational database model?
2. What is a data warehouse?
3. What is OLAP and how is it used in a data warehouse?
4. What is a foreign key and how does it work?
5. What are the different types of relationships in a relational database?
Advanced Database Technologies Database Engineer Interview Questions
1. What is a database schema?
2. What is a NoSQL database?
3. What are the advantages of using NoSQL over relational databases?
4. What is sharding in a database?
5. What is database replication?
Database Security Database Engineer Interview Questions
1. What is database encryption and why is it important?
2. What is role-based access control (RBAC) in databases?
3. How do you ensure database security and protect against SQL injection?
Data Backup & Recovery Database Engineer Interview Questions
1. What is a database backup?
2. What is point-in-time recovery in database management?
3. What is a transaction log and how is it used in recovery?
4. What are the different types of database backups (full, incremental, differential)?
Data Storage & Management Database Engineer Interview Questions
1. What is a relational database?
2. What is a key-value store and when would you use it?
3. What is a data lake?
4. What is the difference between a data warehouse and a database?
5. What are the different storage engines in MySQL?
Database Tools and Technologies Database Engineer Interview Questions
1. What are some commonly used database management systems (DBMS)?
2. What is SQL Server Management Studio (SSMS) used for?
3. What is the difference between MongoDB and MySQL?
4. What are some tools for database migration?
5. What is database profiling, and how is it used for performance tuning?
General Database Engineer Interview Questions
Mastering the basics is key to succeeding in any database-related role. This section covers important Database Engineer Interview Questions focused on general database concepts. Understanding these fundamentals will help you confidently tackle questions about data types, keys, queries, and database structures during your interview.

1. What is a transactional database?
A transactional database is designed to handle transactional operations, typically involving a high level of consistency and accuracy. These databases support transactions that follow the ACID properties (Atomicity, Consistency, Isolation, and Durability). They ensure that database transactions are processed reliably. A common example is an online banking system, where a money transfer between two accounts must be processed as a single transaction.
2. What is an aggregate function in SQL?
Aggregate functions are used to perform calculations on multiple rows of a dataset and return a single result. Common examples include:
COUNT() – Returns the number of rows.
SUM() – Adds up the values in a column.
AVG() – Calculates the average of values in a column.
MAX() – Finds the largest value.
MIN() – Finds the smallest value.
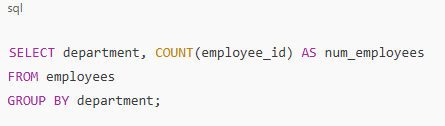
3. What is the difference between CHAR and VARCHAR?
CHAR: A fixed-length string type. It will always allocate the same amount of space, regardless of the actual data length. For example, if you store “John” in a CHAR(10) column, it will store “John ” (padded with spaces).
VARCHAR: A variable-length string type. It uses only the space needed for the data. For example, “John” stored in a VARCHAR(10) column will only occupy 4 characters.
4. What is a database cursor?
A database cursor is a pointer used to fetch, manipulate, and iterate through rows in a result set returned by a query. Cursors are often used in stored procedures or scripts for processing rows one by one.
5. What is a composite key?
A composite key is a combination of two or more columns in a table used to uniquely identify a record. For example, in an orders table, the combination of order_id and customer_id might form a composite key to uniquely identify each order by a specific customer.
6. What is a subquery?
A subquery is a query embedded within another query. It is used to retrieve data that will be used in the outer query. Subqueries are often found in the WHERE, FROM, or SELECT clauses.

7. What is a schema-less database?
A schema-less database, often referred to as a NoSQL database, does not require a fixed schema for its data. This means that each document or entry can have a different structure. This is useful for applications that deal with unstructured or semi-structured data.
8. What are the advantages of using cloud databases?
Cloud databases offer several advantages, including:
- Scalability: They can scale on demand to accommodate growing workloads.
- High Availability: Cloud providers offer redundancy and failover to ensure uptime.
- Cost Efficiency: Pay-as-you-go pricing models can reduce upfront costs.
- Accessibility: Data can be accessed from anywhere via the cloud.
9. What is a timestamp in a database?
A timestamp is a data type used to store the date and time when a record was created or modified. Timestamps help track changes and can be used for auditing or version control.

10. What is data integrity and how is it maintained in a database?
Data integrity refers to the accuracy and consistency of data. It is maintained using constraints like:
- Primary Keys: Ensures each record is unique.
- Foreign Keys: Ensures relationships between tables are valid.
- Unique Constraints: Ensures no duplicate values exist.
- Check Constraints: Ensures data values meet specific conditions.
SQL and Query Optimization
SQL and query optimization are critical skills for any database engineer. This section highlights key Database Engineer Interview Questions focused on SQL security, transaction management, joins, and indexing. Understanding these topics will help you write efficient, secure queries and improve database performance.

11. What is SQL injection and how do you prevent it?
SQL injection is a security vulnerability where an attacker inserts malicious SQL code into an input field, potentially gaining unauthorized access to the database. To prevent it:
- Use parameterized queries.
- Validate and sanitize all user inputs.
- Use stored procedures instead of dynamic SQL.
12. What is a database transaction log?
A transaction log is a sequential record of all changes made to the database. It ensures that any changes made to the database can be rolled back if necessary and is crucial for recovering data in case of a failure.
13. What is the difference between an inner join and an outer join in SQL?
INNER JOIN: Returns only rows that have matching values in both tables.
OUTER JOIN: Returns all rows from one table and the matched rows from the other table. If no match is found, NULL values are returned for the columns of the table with no match.
14. What are the various types of indexes in SQL?
Types of indexes in SQL:
- Unique Index: Ensures that all values in a column are unique.
- Clustered Index: Defines the physical order of data storage in a table.
- Non-clustered Index: Does not affect the physical order of rows but provides a logical ordering for faster query performance.
Explore these helpful interview question guides
Database Design & Modeling Database Engineer Interview Questions
Database design and modeling are fundamental skills for database engineers to structure and organize data effectively. This section covers essential Database Engineer Interview Questions focused on relational models, data warehouses, key relationships, and database structures to help you prepare for interviews and real-world database challenges.

15. What is a relational database model?
The relational database model organizes data into tables (relations), where rows represent records and columns represent attributes. It uses primary and foreign keys to create relationships between tables.
16. What is a data warehouse?
A data warehouse is a large, centralized repository of data designed to support business intelligence and decision-making. It stores historical data from multiple sources in a structured format.
17. What is OLAP and how is it used in a data warehouse?
OLAP (Online Analytical Processing) allows users to interactively analyze multidimensional data. It is used in data warehouses to perform complex queries, aggregations, and reports on large datasets.
18. What is a foreign key and how does it work?
A foreign key is a column (or set of columns) in one table that links to the primary key of another table. It ensures referential integrity by making sure the values in the foreign key column correspond to existing values in the referenced table.
19. What are the different types of relationships in a relational database?
- One-to-one: Each row in one table is linked to one row in another table.
- One-to-many: One row in a table can be linked to many rows in another table.
- Many-to-many: Multiple rows in one table can be linked to multiple rows in another table (requires a junction table).

Advanced Database Technologies Database Engineer Interview Questions
Database Engineer Interview Questions cover essential topics related to database design, management, performance tuning, and security. These questions test your understanding of relational databases, SQL, NoSQL, data modeling, and advanced concepts like indexing, sharding, and replication.
20. What is a database schema?
A schema is the structural blueprint of a database. It defines how the data is organized and includes tables, columns, data types, and relationships between tables. Think of it as a design plan for how a database is laid out.
Example of a simple schema:
Table Name
Column Name
Data Type
Employees
EmployeeID
INT
FirstName
VARCHAR(50)
VARCHAR(50)
LastName
DepartmentID
INT
Here, the schema defines a table called Employees with four columns: EmployeeID, FirstName, LastName, and DepartmentID. Each column has a specific data type.
21. What is a NoSQL database?
NoSQL databases are designed for flexible, scalable storage of unstructured or semi-structured data. They do not rely on relational tables and are commonly used in applications requiring high performance and scalability.
Example NoSQL databases:
- MongoDB: A document-based database that stores data in JSON-like format.
- Cassandra: A wide-column store that is highly scalable for distributed databases.
- Redis: A key-value store used for caching and real-time data processing.
Example of a document in MongoDB (JSON format):

22. What are the advantages of using NoSQL over relational databases?
Advantages:
- Scalability: NoSQL databases like Cassandra and MongoDB can scale horizontally by distributing data across multiple servers.
- Flexibility: NoSQL databases can handle various types of data formats (JSON, key-value, graphs), while relational databases require a predefined schema with tables and strict data types.
- Performance: NoSQL is optimized for high-performance operations like fast reads/writes, especially in distributed applications.
23. What is sharding in a database?
Sharding is the process of splitting a database into smaller, more manageable pieces called shards, which are distributed across different servers. This approach helps with scaling and improving performance by spreading the load.
Example of Sharding in a database: Suppose you have a large e-commerce platform with millions of users. The user data can be split into multiple shards based on user ID ranges:
Shard ID
Users in Shard
Shard 1
Users with ID 1 – 1,000,000
Shard 2
Users with ID 1,000,001 – 2,000,000
Shard 3
Users with ID 2,000,001 – 3,000,000
Each shard operates independently but together they form the entire database. This approach allows the database to handle more users and requests by distributing the load across multiple servers.
24. What is database replication?
Database replication involves creating copies of a database on multiple servers. Replication ensures that data is not lost if one server fails and improves the availability and fault tolerance of the database.
Types of replication:
- Master-Slave Replication: One primary server (master) handles writes, and multiple secondary servers (slaves) replicate the data for read operations.
- Multi-Master Replication: Multiple servers handle writes and replicate data between each other.
Database Security Database Engineer Interview Questions
Database Security is a crucial topic in Database Engineer Interview Questions. This section covers key concepts and best practices to protect databases from unauthorized access and threats. Understanding these security principles is essential for anyone preparing for Database Engineer Interview Questions.

25. What is database encryption and why is it important?
Database encryption involves converting sensitive data into an unreadable format using an encryption key. This ensures that even if an attacker gains unauthorized access to the database, the data remains protected and unreadable unless they have the decryption key.
Importance of Database Encryption:
- Data Protection: It prevents unauthorized access to sensitive data, such as passwords, financial information, and personal details.
- Compliance: Many industries (like healthcare and finance) have strict regulations that require data encryption to protect customer information (e.g., GDPR, HIPAA).
- Mitigating Breach Impact: If a database is compromised, encrypted data is useless without the decryption key, reducing the impact of a breach.
Example:
Before encryption: Password = ‘John123’
After encryption: EncryptedPassword = ‘D0aB@59f3jkdj!l4’
26. What is role-based access control (RBAC) in databases?
Role-Based Access Control (RBAC) is a system for managing access to database resources based on the roles assigned to individual users. Instead of assigning permissions directly to users, RBAC assigns permissions to roles, and users are granted access by being assigned to specific roles.
How it works:
Roles are defined (e.g., Admin, User, Read-only).
Permissions (such as SELECT, INSERT, UPDATE, DELETE) are assigned to roles.
Example:
Role
Permissions
Admin
SELECT, INSERT, UPDATE, DELETE
Manager
SELECT, UPDATE
Employee
SELECT
An Admin role can perform all operations, while an Employee role can only read data.
27. How do you ensure database security and protect against SQL injection?
SQL injection is a security vulnerability that allows attackers to manipulate a database query by injecting malicious SQL code. Here are several ways to protect against SQL injection:
- Parameterize Queries:
Parameterized queries ensure that user input is treated as data, not executable code. By using placeholders for user inputs, the database treats them as values instead of part of the SQL code.
Example (using prepared statements):

- Use Stored Procedures:Stored procedures are precompiled SQL queries that help reduce the risk of SQL injection because user input is treated as parameters rather than being directly embedded in SQL statements.
Example (Stored Procedure):

Data Backup & Recovery Database Engineer Interview Questions
In this section, you will find important Data Backup & Recovery Database Engineer Interview Questions that focus on protecting and restoring data in databases. Understanding backup types, recovery methods, and transaction logs is essential for any database engineer to ensure data safety, integrity, and availability in case of failure or corruption.

28. What is a database backup?
A database backup is a copy of the database that can be restored in case of data loss or corruption. Backups are typically stored on different media or in remote locations to ensure that the data is safe even if the primary system fails.
Types of Backups:
- Full Backup: A complete copy of the entire database.
- Incremental Backup: Backs up only the data that has changed since the last backup (whether full or incremental).
- Differential Backup: Backs up data that has changed since the last full backup.
29. What is point-in-time recovery in database management?
Point-in-time recovery allows a database to be restored to a specific moment in the past, using transaction logs to apply or roll back data until the desired point. This is crucial for recovering from accidental data modifications, deletions, or system crashes.
How it works:
- Back up the Database: Take a full backup.
- Store Transaction Logs: Keep logs of all database changes after the backup.
- Recover: When needed, restore the database from the backup, then use transaction logs to bring it to a specific point in time.
Example: If a mistake occurs on January 15th, but the backup was taken on January 10th, point-in-time recovery can restore the database back to the state it was on January 15th.
30. How do you perform database recovery?
Database recovery involves restoring the database from backups, applying transaction logs, and ensuring the database is in a consistent state.
Steps for Recovery:
- Restore from Backup: Restore the last full backup.
- Apply Transaction Logs: Use transaction logs to bring the database back to the state just before the failure (for point-in-time recovery).
- Verify Consistency: Run checks to ensure the data is consistent and correct.
31. What is a transaction log and how is it used in recovery?
A transaction log records all changes made to the database, including insertions, updates, and deletions. It plays a critical role in recovery by providing a record of transactions that can be used to restore data to its most recent consistent state.
How it works:
During a transaction, changes are first written to the transaction log.
In the event of a failure, the transaction log can be used to:
- Redo committed transactions (ensure they are applied).
- Undo uncommitted transactions (remove any partial changes).
32. What are the different types of database backups (full, incremental, differential)?
Backup Type
Column Name
Data Type
Full Backup
A complete backup of the entire database.
Used as a base for recovery.
Incremental Backup
Backs up only changes since the last backup (whether full or incremental).
Efficient for large databases, saves space.
Differential Backup
Backs up changes since the last full backup.
Provides a balance between full and incremental backups.
Example:
- Full Backup: Every Sunday.
- Incremental Backup: Every weekday, only backs up changes since Sunday.
- Differential Backup: Every weekday, backing up changes since the last Sunday.
Data Storage & Management Database Engineer Interview Questions
This section covers essential Data Storage & Management – Database Engineer Interview Questions focused on different types of databases, storage mechanisms, and data organization techniques. These questions help assess understanding of relational databases, NoSQL stores, data lakes, warehouses, and storage engines used in database management systems.

33. What is a relational database?
A relational database stores data in tables, with rows and columns, and uses Structured Query Language (SQL) to manage and query the data. Each table represents an entity, and relationships between tables are defined using primary keys (unique identifiers) and foreign keys (references to primary keys in other tables).
In the example above, Customer_ID is the primary key in the Customers table and a foreign key in the Orders table.
Example:
Customers
Customer_ID (PK)
Name
Phone
1
Alice
alice@mail.com
1234567890
2
Bob
bob@mail.com
0987654321
Orders
Order_ID (PK)
Customer_ID (FK)
Amount
Date
1
1
150.00
2025-04-01
2
2
250.00
2025-04-02
In the example above, Customer_ID is the primary key in the Customers table and a foreign key in the Orders table.
34. What is a key-value store and when would you use it?
A key-value store is a type of NoSQL database where data is stored as a collection of key-value pairs. Each key is unique and is used to retrieve the corresponding value. Key-value stores are highly efficient for use cases requiring fast retrieval by key, such as caching, session management, and storing simple configurations.
Example:
Key: user123
Value: { “name”: “Alice”, “age”: 30, “location”: “Regina” }
When to use:
- Caching: Store frequently accessed data in memory for fast retrieval.
- Session Management: Store user sessions where each session ID is a unique key.
35. What is a data lake?
A data lake is a large, centralized repository designed to store raw, unstructured, or semi-structured data in its native format. It enables businesses to store vast amounts of data without worrying about predefined schemas, making it ideal for big data analytics and machine learning.
Example: A data lake might store a variety of data, such as:
- Raw logs from web servers (unstructured data)
- SON documents from customer interactions (semi-structured data)
- CSV files from IoT sensors (structured data)
Key Characteristics:
- Scalability: Can scale to store petabytes of data.
- Flexibility: Data can be in any format (JSON, XML, text).
- Analytics Ready: Facilitates advanced analytics and big data processing.
36. What is the difference between a data warehouse and a database?
Database: Primarily used for day-to-day transactional data (e.g., sales, customer orders). It supports real-time processing and is optimized for quick, small queries and transactions.
Data Warehouse: A repository for historical data that supports complex queries and business intelligence. It is optimized for analytical processing and stores large amounts of data collected from multiple sources for reporting and analysis.
37. What are the different storage engines in MySQL?
Storage Engine
Description
InnoDB
Default storage engine, supports ACID transactions, foreign keys, and row-level locking.
MyISAM
Used for non-transactional tables, full-text indexing support.
Memory
Stores data in memory, fast but no persistence (data is lost after shutdown)
CSV
Data is stored in CSV files. Useful for exporting/importing data
Database Tools and Technologies Database Engineer Interview Questions
This section features important Database Tools and Technologies Database Engineer Interview Questions that explore various database management systems, tools, and technologies used by database engineers. It covers topics such as popular DBMS options, tools like SQL Server Management Studio, differences between NoSQL and relational databases, database migration tools, and performance profiling techniques.

38. What are some commonly used database management systems (DBMS)?
Relational DBMS: MySQL, PostgreSQL, Oracle, SQL Server.
NoSQL DBMS: MongoDB, Cassandra, Redis, Couchbase.
39. What is SQL Server Management Studio (SSMS) used for?
SQL Server Management Studio (SSMS) is an integrated environment for managing SQL Server databases. It allows database administrators and developers to:
- Write and execute SQL queries
- Design databases and tables
- Manage backups and restores
- Monitor server performance
- Tuning database queries
SSMS is a powerful tool for both managing and developing within Microsoft SQL Server environments.
40. What is the difference between MongoDB and MySQL?
Aspect
Column Name
Data Type
Database Type
NoSQL, document-oriented
Relational database
Data Model
Stores data in JSON-like documents
Data stored in structured tables with rows and columns
Schema
Schema-less, flexible
Fixed schema, requiring predefined structure
Query Language
Query documents using MongoDB Query Language (MQL)
SQL (Structured Query Language)
41. What are some tools for database migration?
Tools for database migration include:
- AWS Database Migration Service (DMS)
- Liquibase
- Flyway
- Redgate SQL Compare
- Database Migration Toolkit (DMT)
42. What is database profiling, and how is it used for performance tuning?
Database profiling involves collecting performance data to analyze query execution times, resource consumption (CPU, memory, disk I/O), and identifying slow queries or bottlenecks. Profiling tools help database administrators optimize performance by:
Improving query efficiency (e.g., optimizing JOINs, adding indexes)
Monitoring resource usage (e.g., optimizing memory allocation)
Identifying and addressing database contention
Prepare Like a Pro: Interview Prep with AI Assistance
With the help of AI Assistant, you can sharpen your interview skills and receive personalized feedback. Start practising with our AI Mock Interview Practice sessions to simulate real-world scenarios and boost your confidence, while our AI Questions and Answer Generator tailors your preparation to the job you’re aiming for. By using these tools, you’ll gain invaluable insight into your strengths and areas for improvement.
Ready to take your interview skills to the next level? Start practicing today!
Top 40+ Database Engineer Interview Questions
Table of Contents
Recommended Resources

Junior Web Designer Interview Questions

Top 50 AI Engineer Interview Questions

Top 30 IT Project Manager Interview Questions

Top 35 Account Manager Interview Questions You Must Prepare

Top 50 System Administrator Interview Questions

Top 40 Marketing Analyst Interview Questions You Must Prepare